| Übersicht - Inhaltsverzeichnis | |
| 1 | Beschreibung des Projekts, Projektziele |
| 2 | Teilprojekt 1: Web - Server - MP3-/Wave-File |
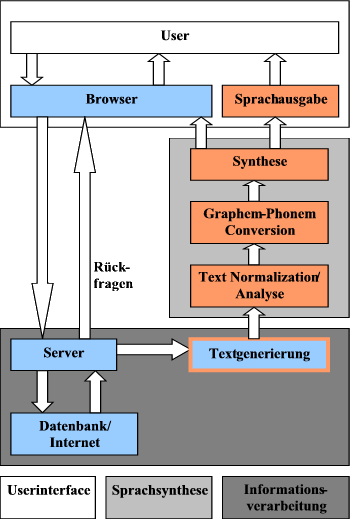
| 2.1 | ABB. 1: Schematische Darstellung des Projekts |
| 2.2 | Kurze Beschreibung des Projekts |
| 2.3 | Installation - Voraussetzungen |
| 2.3.1 | Installation: Sprachsynthese |
| 2.3.1.1 | Installation: Speech-Tools |
| 2.3.1.2 | Installation: Festvox |
| 2.3.1.3 | Installation: Festival |
| 2.3.1.4 | Installation: Festival/IMS |
| 2.3.2 | Installation: Server (bin-Ordner) |
| 2.3.3 | Installation: PHP (Einstellungen) |
| 2.3.4 | Installation: MP3-Encoder (lame) |
| 2.3.5 | Installation - Automatische Installation |
| 2.4 | Programmierung |
| 2.4.1 | Generierung der Texte |
| 2.4.2 | Parsen der HTML-Seite |
| 2.5 | Zusammenfassung Teilprojekt 1 |
| 3 | Referenzen |
| 3.1 | Literatur |
| 3.2 | Links |
Ziel des Projektes war es, für eine begrenzte Domäne (realisiert für die Domänen Fahrplanauskunft und Wettervorhersage) ein Auskunftssystem mit Sprachausgabe (gesprochene Sprache) zu entwickeln.
In dem hier beschriebenen Teilprojekt 1 gibt der User über eine html-Seite (html-form) seine Anfrage ein, ein Serverskript wertet diese aus, und versucht, die nötigen Daten aus einer Datenbank oder direkt aus dem Internet zu beschaffen und daraus einen natürlichsprachigen Antworttext zu generieren. Aus diesem wird im Bereich Sprachsynthese ein Audio-File generiert, das beim User über Browser-Plug-In oder im externen Wave-Player abgespielt werden kann. Die Sprachsynthese beruht auf dem Projekt Festival der Universität Edinburgh und der Weiterentwicklung festvox, die die Schaffung eigener Stimmen für Festival unterstützt und erleichtert (im weiteren Verlauf des Textes als Teilprojekt 1 bezeichnet).
Die Beschreibung erfolgt beispielshaft anhand der Fahrplansauskunft (VRN). Über ein Webinterface, das an die Benutzeroberfläche von VRN angelehnt ist, lässt sich eine Anfrage starten (vgl. Abb. 1):
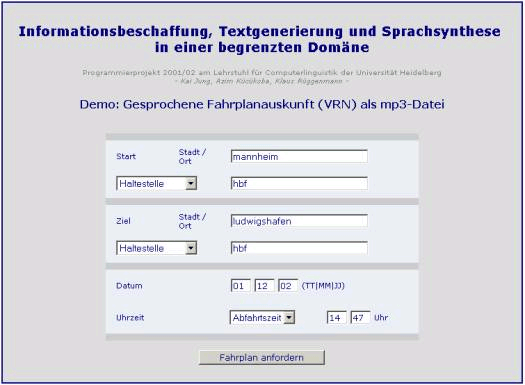
Die Anfrage geht an eine php-Datei und wird zum VRN-Server weitergeleitet. Die resultierende HTML-Seite wird geparst und analysiert, dabei können verschiedene Fälle auftreten:
| a. | Seite korrekt, die Daten waren korrekt, Rückgabe von wav/mp3-Datei bzw. Seite mit Link auf Audio-Datei. |
| b. | Start-Ort, Start-Haltestelle bzw. Ziel-Ort/-Haltestelle wurden nicht erkannt bzw. ergaben zu viele mögliche Treffer. |
| c. | Start-Ort/-Haltestelle bzw. Ziel-Ort/-Haltestelle sind mehrdeutig, der Benutzer muss nochmals eine manuelle Auswahl treffen. |
| d. | Keine Seite/andere Probleme, z.B. Server down etc., es wird eine Standard-Fehlermeldung zurückgegeben. |
| e. | Die Angaben waren unvollständig, d.h., nicht alle Pflicht-Felder waren ausgefüllt. |
Im Fall a. oder d. erfolgt die Rückgabe einer Audio-Datei, im Fall b. oder c. werden weitere Eingaben vom Benutzer erwartet, die hier in Teilprojekt 1 natürlich wieder nur über eine Tastatur-/Maus-Eingabe erfolgen können.
Das php-Skript erfordert zum Funktionieren eine korrekte Installation von Festival, und zwar in der vom IMS Stuttgart erweiterten Variante. Dazu müssen die Speech-Tools (und festvox) installiert sein, gleichzeitig die Speech-Engine von MBROLA mit den dazugehörigen Stimmen. Um eine Ausgabe nicht nur als PCM-, sondern auch komprimiert als mp3-Datei zu ermöglichen, muss ein entsprechender Encoder vorhanden sein (die Probleme mit möglichen Copyright-/Patentverletzungen aufgrund fehlender Lizenzierungen der üblichen Freeware-Tools bleibt hier unberücksichtigt).
Zu bedenken ist, dass sich die Größenordnung bei vollständiger Installation schnell in Bereiche von über 60-100 MB an Daten ausweiten kann, wodurch der Dateidownload bei geringerer Badbreite wohl besser direkt auf dem Server mit "wget ..." erfolgen sollte (Eine Datei mit den Download-Anforderungen für die Tools, Programme und Daten für den Bereich Sprachsynthese findet sich in res/wget.txt).
Der Bereich Sprachsynthese geht näher auf die Installation der Bereiche ein,
die mit Sprachsynthese zu tun haben, dazu zählen die Edinburgh speech-tools, Festival,
Festvox und die Festival-Erweiterung des IMS Stuttgart.
Mit den kurzen Ausführungen lässt sich schnell ein funktionierendes System aufbauen.
Bei weiteren Fragen finden sich noch zahlreiche Informationen in den entsprechenden
INSTALL- und README-Dateien.
Die Speech-Tools werden mit für Red-Hat-Linux angepassten Makefiles geliefert, eine Installation unter Suse Linux (getestet mit 7.2) funktioniert jedoch problemlos, wenn vorher die Datei libtermcap.a in den Ordner ~/speech_tools/lib/ kopiert wird (sonst wird der Kompilierungsvorgang mit Fehlern abgebrochen; eine Kopie der Datei libtermcap.a befindet sich auch im Projekt-Unterordner "pre/").
Dann der übliche Ablauf, jeweils mit der Bezeichnung des entsprechenden GNU-Tools:
unix$ ./configure
unix$ gmake
unix$ gmake test
Die Installation von Festvox wird hier nicht beschrieben, weil die Festvox-Distribution nicht installiert werden muss, wenn Sprachsynthese nur mit fertigen Stimmen erfolgen soll. Wenn jedoch die Stimmen verändert/erweitert werden sollen, um z.B. eigene Stimmen für begrenzte Domänen (was ja Teil unserer ursprünglichen Zielsetzung war) zu erzeugen, muss auch Festvox installiert werden.
Zur Installation werden folgende Dateien vorausgesetzt:
Speech Tools (s.o.),
festlex_NAME.tar.gz -> lexicon
festvox_NAME.tar.gz -> a speech
Um die Installation zu testen (gmake test), müssen auch folgende Dateien installiert/entpackt sein:
festlex_CMU.tar.gz
festlex_OALD.tar.gz
festlex_POSLEX.tar.gz
festvox_don.tar.gz
festvox_kedlpc16k.tar.gz
festvox_rablpc16k.tar.gz
Nach erfolgreicher Installation sollte Festival gleich in der Lage sein,
einen Satz auszugeben, wenn es richtig konfiguriert ist und keine Probleme mit
der Audio-Hardware hat (ist bei uns noch nicht vorgekommen):
festival> (SayText "hello world")
oder:
festival> (intro)
Ein Problem ist, dass die Daten erst nach kurzer Registrierung über einen speziell eingerichteten Link zum Download freigegeben werden. Die zu installierenden Dateien befinden sich jedoch auch innerhalb von "deps/" im Projektordner, eine Installation und das Starten des Programms kann jedoch nur im Rahmen der gültigen Lizenz-Bestimmungen des Programms, die auf den Seiten des IMS Stuttgart nachgelesen werden können, erfolgen.
Folgende Dateien ins Festival-Hauptverzeichnis entpacken:
'ims_german_1.2-os.tgz' The sources and scheme file for the IMS German Festival
'ims_german_1.2-doc.tgz' The documentation for the IMS German Festival
'bomp_full.tgz' The BOMP lexicon provided by the IKP, University of Bonn
'festival-1.4.1-fixes.tgz' Bug Fixes
Folgende Schritte sind nötig:
Die MBROLA-ENGINE und mindestens eine Stimme installieren (s. Ordner MBROLA)
Die folgende Zeile der Festival Konfigurationsdatei (festival/config/config) hinzufügen:
ALSO_INCLUDE += ims_german_text
Das Hauptverzeichnis mit der MBROLA-Installation (z.B. /usr/local/MBROLA/) in der Datei sitevars.scm hinzufügen:
(set! mbrola-path "/usr/local/MBROLA/")
(set! mbrola_progname (string-append mbrola-path "mbrola -e"))
Zur Datei siteinit.scm (festival/lib/siteinit.scm) hinzufügen:
(require 'ims_german_opensource)
Wenn eine der Dateien nicht existieren sollte, dann einfach eine leere Datei anlegen.
Die Dateien mit den Bug-Fixes aktualisieren:
touch `gtar ztf TGZ_DIRECTORY/festival-1.4.1-fixes.tgz`
Danach müssen auch die Speech-Tools neu kompiliert werden.
cd speech_tools
gmake info
gmake make_library ...
Dann muss Festival nochmals kompiliert werden
cd festival
gmake info
gmake
Wenn man weiß, dass die Programme auf dem laufenden System funktionieren,
empfiehlt es sich natürlich die Reihenfolge zu verändern.
Ein laufender Server muss natürlich installiert sein, um CGI-Skripte oder PHP-Skripte ausführen zu können. Wo die Installation von Festival auf dem Server erfolgen sollte, hängt natürlich von Server und -konfiguration ab. Häufig lassen die Sicherheitseinstellungen nur ein Ausführungs-/"bin"-Verzeichnis zu.
U.U. könnte es zu Problemen kommen, z.B. je nach Einstellungen für Umgebungsvariablen etc., außerdem wird bei unserer Lösung Festival über "exec" aufgerufen, was u.U. auch erst freigegeben sein muss.
Hierüber sind im Moment keine Informationen verfügbar.
Bisher gibt es hierfür nur eine Textdatei (pre/sonstiges/wget.txt), die man mit wget aufrufen kann, um die Programme/Daten/Stimmen etc. im Bereich Sprachsynthese auf einem Server downzuloaden.
Zur Programmierung am besten direkt den Quellcode anschauen und die eingefügten Kommentare.
Welche Texte für mögliche Fahrplauskünfte nötig sind, wird im folgenden anhand eines Beispiels gezeigt:
Beispiel-Antwort
Start-Ort: Ludwigshafen/Rhein
Start-Haltestelle: Bahnhof Mundenheim
Ziel-Ort: Heidelberg
Ziel-Haltestelle: Rathaus/Bergbahn
18:19 ab LU-Mundenheim, Bahnhof Bus 154
18:30 an Ludwigshafen, Berliner Platz Ludwigshafen, Berliner Platz
Fahrzeug behindertengerecht
18:32 ab Ludwigshafen, Berliner Platz Straßenbahn MVV 3
18:37 an Mannheim, Hbf Sandhofen, Endstelle
18:45 ab Mannheim, Hbf RE 3843
18:57 an Heidelberg, Hbf Heilbronn Hbf
Fahrradmitnahme begrenzt möglich
ab Heidelberg, Hbf ca. 7 Minuten
an Heidelberg, Betriebshof
19:07 ab Heidelberg, Betriebshof Bus 35
19:17 an Heidelberg, Alte Brücke Neckargemünd, Bildungszentrum
Fahrzeug behindertengerecht
ab Heidelberg, Alte Brücke ca. 5 Minuten
an Heidelberg, Rathaus/Bergbahn
Der zu generierende Text lautet dann (zur besseren Übersicht ist die Antwort-Tabelle von VRN nochmals jeweils vorangestellt):
Ihre Verbindung von Ludwigshafen-Mundenheim, Haltestelle Bahnhof, nach Heidelberg, Haltestelle Rathaus/Bergbahn:
18:19 ab LU-Mundenheim, Bahnhof Bus 154
18:30 an Ludwigshafen, Berliner Platz Ludwigshafen, Berliner Platz
Zuerst ab Ludwigshafen Mundenheim, Haltestelle Bahnhof mit dem Bus 154, in Richtung Ludwigshafen Berliner Platz, nach Ludwigshafen, Berliner Platz. Fahrzeit von 18 Uhr 19 bis 18 Uhr 30.
18:32 ab Ludwigshafen, Berliner Platz Straßenbahn MVV 3
18:37 an Mannheim, Hbf Sandhofen, Endstelle
Weiterfahrt mit der Straßenbahn MVV 3 in Richtung Sandhofen Endstelle nach Mannheim, Haltestelle Hauptbahnhof. Fahrtzeit von 18 Uhr 32 bis 18 Uhr 37.
18:45 ab Mannheim, Hbf RE 3843
18:57 an Heidelberg, Hbf Heilbronn Hbf
Weiterfahrt mit dem Regionalexpress 3843 in Richtung Heilbronn Hauptbahnhof nach Heidelberg, Haltestelle Hauptbahnhof. Fahrtzeit von 18 Uhr 45 bis 18 Uhr 57.
ab Heidelberg, Hbf ca. 7 Minuten
an Heidelberg, Betriebshof
Es folgt ein Fußweg von ca. 7 Minuten nach Heidelberg, Betriebshof.
19:07 ab Heidelberg, Betriebshof Bus 35
19:17 an Heidelberg, Alte Brücke Neckargemünd, Bildungszentrum
Weiterfahrt mit dem Bus 35 in Richtung Neckargemünd, Bildungszentrum Heilbronn Hauptbahnhof nach Heidelberg, Haltestelle Hauptbahnhof. Fahrtzeit von 18 Uhr 45 bis 18 Uhr 57.
ab Heidelberg, Alte Brücke ca. 5 Minuten
an Heidelberg, Rathaus/Bergbahn
Es folgt ein Fußweg von ca. 5 Minuten nach Heidelberg, Rathaus Bergbahn.
Aus diesem (komplexen) Beispiel ergeben sich schon bestimmte Templates, aus denen der Antworttext generiert wird:
| - | Am Anfang (Start-Template): Ihre Verbindung von "Start" nach "Ziel": |
| - | Erster Satz: Zuerst ab "Start" mit "Verkehrsmittel" nach "Ziel" Fahrzeit von "Startzeit" bis "Ankunftszeit". |
| - | Bei Fusswegen: Es folgt ein Fußweg von "Dauer" nach "Ziel". |
| - | Bei Verbindungen mit Bus oder Bahn: Weiterfahrt mit "Verkehrsmittel" nach "Ziel". Fahrtzeit von "Startzeit" bis "Zielzeit" |
Dazu müssen bestimmte Teile des Textes normalisiert werden, z.B. Uhrzeiten, Abkürzungen (RE: Regionalexpress, RB: Regionalbahn etc.). Beim Parsen der Verbindungstabelle werden die Daten zweier zugehöriger Tabellenzeilen in ein Verbindungsobjekt geschrieben, das aus Startzeit, Startort, Starthaltestelle, Zielort, Zielhaltestelle, Zielzeit und Verkehrsmittel besteht. Diese Daten werden dann in die Templates eingefügt.
Um den Wiedergabetext nicht unermesslich lange werden zu lassen, wird immer nur die erste Verbindung angesagt. Probleme ergeben sich auch durch zu viele Informationen, wie z.B. im Satz:
Weiterfahrt mit dem Bus 35 in Richtung Neckargemünd, Bildungszentrum Heilbronn Hauptbahnhof nach Heidelberg, Haltestelle Hauptbahnhof,
in dem die Häufung von Hauptbahnhof u.U. das Verständnis des Satzes erschwert. Das spricht auch dafür, dass die Templates noch nicht den nötigen Grad an Differenzierung aufweisen, den eine entsprechende Anwendung in einem realen Einsatz haben müsste.
Die unter 2.2. b. bis d. angesprochenen anderen Fälle laufen entsprechend ab, bei Mehrdeutigkeiten wird die Tabelle von VRN einfach an den Benutzer weitergeleitet.
2.4.2 Parsen der HTML-SeiteProbleme ergeben sich mit dem Parsen der HTML-Seite, jedoch ist der gesuchte Bereich sehr gut einzugrenzen, weil sich der Anker <a name="ROUTE_1"> innerhalb einer Tabelle befindet, deren Anfang und Ende den Bereich der HTML-Seite mit der gewünschten Verbindung eingrenzen. Dieser Bereich wird mit dem eingebauten XML-Parser von PHP geparst, der die oben schon genannten Verbindungs-Objekte anlegt, die danach in die Templates eingefügt werden.
Dazu werden mit den xml_set_element_handler()-Funktionen die Handler-Funktionen für Start- und End-Tags festgelegt und die Funktion, die für den Text zwischen den Tags aufgerufen wird (character_data_handler):
xml_set_element_handler($parser, 'start_element', 'end_element');
xml_set_character_data_handler($parser, 'character_data');
Immer wenn eine neue Zeile (Tag <tr>) anfängt, wird überprüft, ob die letzte Zeile das Ende einer Verbindung war und ein neues Verbindungs-Objekt in das Array "Verbindungen" geschrieben. Aus diesem Array werden dann am Ende Sätze gebildet, indem die Informationen in Satz-Templates eingefügt werden.
Zusammenfassend lässt sich sagen, dass, wenn die Installation der Sprachsynthese-Einheit erst einmal gelungen ist, sich sehr schnell und unproblematisch kleine Anwendungen für die unterschiedlichsten Anwendungsbereiche entwickeln lassen.
Um ein allgemeines Programm zu schreiben, mit dem sich solche Anwendungen entwickeln lassen, müsste es in drei Bereichen zusätzliche Abstraktionsebenen geben:
- Ebene der Daten: die fest kodierten Klassen "Verbindung" oder im Wetterbeispiel "Auskunft" (Weil donnerwetter.de jedoch schon ganze Sätze zurückgibt, erübrigt sich dieses Objekt, wäre jedoch normalerweise: Tag, Stadt, Uhrzeit, Temperatur, Windstärke, Windrichtung etc.) müssten dynamische Datenstrukturen sein (u.U. mit xml zu beschreiben, wobei jedoch sehr schnell ein Dialog entsteht, bei dem auch Entscheidungen (Kombination von verschiedenen Informationen ergibt eine andere Antwort) und eine Form von Schleifen (Verbindungen können aus einer unterschiedlichen Anzahl Teilverbindungen bestehen) vorhanden sein müsste.
- Ebene des Parsens/der Informationsbeschaffung: Die Daten sollten aus html-Seiten auslesbar oder aus Datenbanken zu beschaffen sein, dazu müssten die Bestandteile einer HTML-Seite so klassifizierbar sein, dass eine eindeutige Zuordnung Tags - Daten möglich wäre und auch die unterschiedliche Länge und Häufigkeit von bestimmten Tags, z.B Tabellenzeilen wie im Falle der Einzelverbindungen berücksichtigt werden könnte.
- Ebene der Benutzerinteraktion: Die Ein-/Ausgabe müsste so erfolgen, dass das Skript auch von einer Anwendung, die mit dem Benutzer z.B. über Spracherkennung interagiert, benutzbar sein könnte, d.h., die Sprachsynthese sollte völlig von der Sprachgenerierung getrennt sein.
Was die Installation erleichtern könnte, wäre ein Installationsskript, welches automatisch die Dateien in die richtigen Verzeichnisse kopieren, Konfigurations- und Kompilierungsaufgaben übernehmen könnte. Wir haben das nur mit dem Download der Dateien mit einer Datei für den wget-Befehl realisiert.
Im Rahmen des Studienprojektes konnten wir die angesprochenen Ziele und Verbesserungsmöglichkeiten aus zeitlichen Gründen leider nicht mehr realisieren.