Projektbeschreibung und Zielsetzung:
Das Sprachverarbeitungsprogramm PLAIN (Programs for Language Analysis and Inference, cf. Hellwig 1980) beinhaltet ein deduktives Frage-Anwort-System, maschinelle Übersetzung, Grammatikprüfung und automatische Textzusammenfassung.
Die zugrunde liegende linguistische Theorie ist die Dependency Unification Grammar (DUG), eine Valenzgrammatik mit Lexikon und Dependenzstruktur). Die Syntax-Komponente in PLAIN enthält ein Set von Templates und ein Set von Syntax Frames (Synframes). Ein Synframe stellt ein Set von syntagmatischen Beziehungen dar, die mit dem Wort zur gleichen Zeit kombiniert werden. Sie bestehen aus Komplementen und Adjunkten und werden durch beliebige Referenzen auf Komplement- oder Adjunkt-Templates dargestellt. Auf der Grundlage des Collins Cobuild English Dictionary soll ein Valenzlexikon für das Englische erstellt bzw. vervollständigt werden. Jedem Eintrag im Wörterbuch soll ein Synframe zugeordnet werden.
Das PLAIN Syntax Tool ist eine Eingabemaske, wodurch das Kodieren der Lexeme erleichtert und beschleunigt wird. Ein Synframe entsteht, indem ein entsprechender Eintrag im Wörterbuch (z. B. Collins Cobuild) in ein Synframe umgewandelt und in einen Klammerausdruck überführt wird.
Beispiel:
"The HEAD of a company or organization is the person in charge of it."
wird zu:
(lexeme[head] reading[leader] category[noun]
(complement[+prep_compl] lexeme[of]))
Ohne das PLAIN Syntax Tool muß der Kodierer den gesamten Klammerausdruck von Hand erstellen. Durch das Tool soll das Kodieren der Synframes einfacher und schneller werden. Der Benutzer kann Lexeme, Category etc. über eine Eingabemaske eingeben, der Klammerausdruck wird vom Tool automatisch erstellt. Außerdem sollen Hilfefiles zur Verfügung stehen, und das Tool erstellt eine Liste aller bereits kodierten Lexeme und löscht eventuell doppelt kodierte Einträge.
Als Programmiersprache wurde Python gewählt. Das PLAIN-System ist größtenteils in C/C++ programmiert, eine Integrierung ist zwar möglich, aber nicht vorgesehen, da das PLAIN Syntax Tool unabhängig verwendet wird. Alle im Tool verwendeten bzw. verarbeiteten Dateien sollen im Textformat vorliegen, so können sie später vom PLAIN-System verarbeitet werden.
Zielgruppe für das Verwenden des Tools sind Linguisten, die (teilweise) mit dem PLAIN-System vertraut sind.
Das wichtigste Ziel bei der Entwicklung des Tools war es, das Erstellen der Synframes für den Kodierer so einfach und schnell wie möglich zu machen. Nach einer ersten Testversion zeigte sich, daß das Überführen in den korrekten Formalismus (Klammerausdruck), Wortliste und Doublettenprüfung gut funktionierten. Schwieriger war es, die Eingabemaske optimal zu gestalten, so daß der Kodierer möglichst zeitsparend arbeiten kann. Das Design der Eingabemaske wurde daher mehrmals verändert und getestet, um ein optimales Ergebnis zu erzielen. Gerade beim Kodieren der Synframes ist zeitsparendes Arbeiten wichtig, denn wenn für jeden Eintrag im Wörterbuch ein Synframe erstellt werden muß, ist dies mit großem Zeitaufwand verbunden.
Da das PLAIN-System in Kürze überarbeitet und wieder verwendet werden soll, wird auch das PLAIN Syntax Tool zum Einsatz kommen.
Dokumentation der Dateiformate:
Der
Quellcode des PST besteht aus einer Datei namens startPST.py mit Mainfunktion
und 17 Unterfunktionen. Die Mainfunktion öffnet das erste Fenster der PST GUI
und beinhaltet die Variable tk, die den Parent aller anderen Fenster darstellt.
Von diesem ersten Fenster aus, werden je nach Auswahl des Benutzers die GUI
Funktionen tkhelp() (zum öffnen der Hilfedatei über die Funktion openhelp() )
und openpro() (öffnet eine Projektdatei über openprofile()
und das zweite Auswahlfenster).
Das durch openpro() geöffnete Fenster besteht unter anderem aus vier Buttons,
die weitere Funktionen rufen. wordlist() gibt eine Datei mit allen bereits
codierten Wörtern in einem neuen Fenster aus. check_doublettes() findet alle
doppelt codierten Einträge und löscht sie. save_project() speichert den
gesamten Text des Text-Widgets in einer vom Benutzer gewählten Datei.
Für die Arbeit mit PST besonders wichtig ist die GUI Funktion newentry(), da
diese das Fenster zum Erstellen neuer Synframes wiedergibt. Die Globalen
entrylexeme1, entryreading2, entrycategory3 und entryexample4 stellen Variable
der vier Entry-Widgets dar, die später in der Funtion savene() ausgelesen
werden. Über Buttons können Hilfe-Fenster zum Thema allgemeine Hilfe (tkhelp()
s.o.) und Entscheidungshilfe zum Finden der geeigneten Kategorie (catfwindow()
über opencatf() ) ausgewählt werden. Das Listbox-Widget zur Auswahl geeigneter
Rollen besteht aus einer Liste von Zeilen der roles.txt Datei, die über
openroles() zurückgegeben wird. Im Listbox-Widget existiert ein Event der über
click_right() ein in newentry() erstelltes Auswahlmenü an der mit rechts
geklickten Stelle ausgibt. Hier hat man die Auswahl ein Lexem zu einem
Complement bzw. Adjunct hinzuzufügen oder ein Adjunct in ein Expected_Adjunct
zu verwandeln. Bei ersterer Wahl öffnet sich ein kleines Fenster durch
r_add_lex(), das die Eingabe eines Lexems erwartet und über den Button „Save
& Close“ in der Funktion save_lex() in einem globalen Dictionary
D_item_lex gespeichert wird. Bei letzterer Wahl wird die Funktion r_expected()
gerufen, die die Zeilenauswahl in einer globalen Liste ex_position speichert.
Über den Button „Show Selection“ wird die Funktion selection() gerufen, die
in einem Label-Widget die Auswahl des Listbox-Widgets ausgibt. Hierbei wird mit
den Globalen showsel und labelselect gearbeitet, wobei in showsel die Auswahl
gespeichert ist und über labelselect das Label-Widget konfiguriert werden kann.
Gespeichert und weiterverarbeitet wird über den Button „Add New Entry“.
Dieser ruft savene(), die zentrale Funktion im Hintergrund des PST. Die Globalen
entrylexeme1, entryreading2, entrycategory3, entryexample4 und listbox werden
hier ausgelesen, das Dictionary D_item_lex und die Liste ex_position werden
verarbeitet. Ein neuer Synframe wird erstellt und im Text-Widget des
Projekt-Fentsters (openpro()) wiedergegeben.
Beispiel:
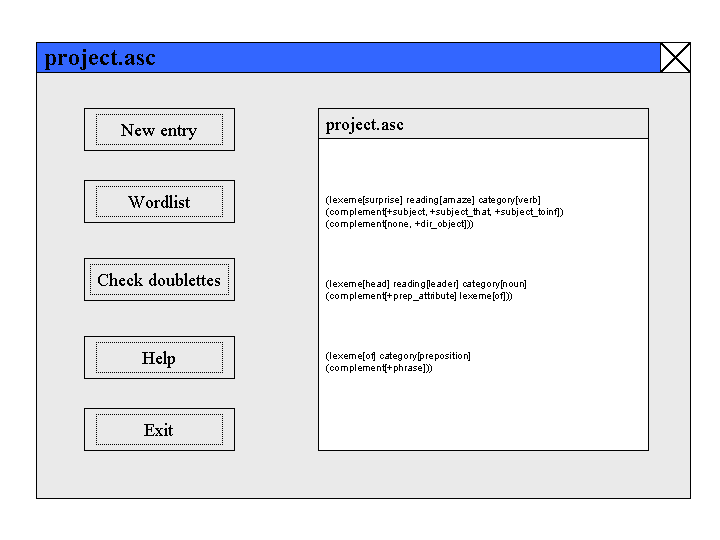
Zuerst öffnet der Benutzer die Projektdatei, die er bearbeiten möchte. Sie wird in einem Fenster angezeigt.
Über "New Entry" kann ein neuer Eintrag erstellt werden:
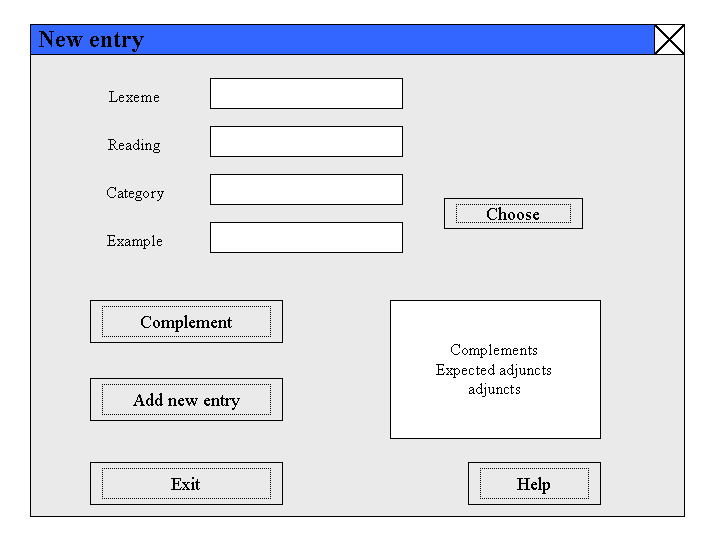
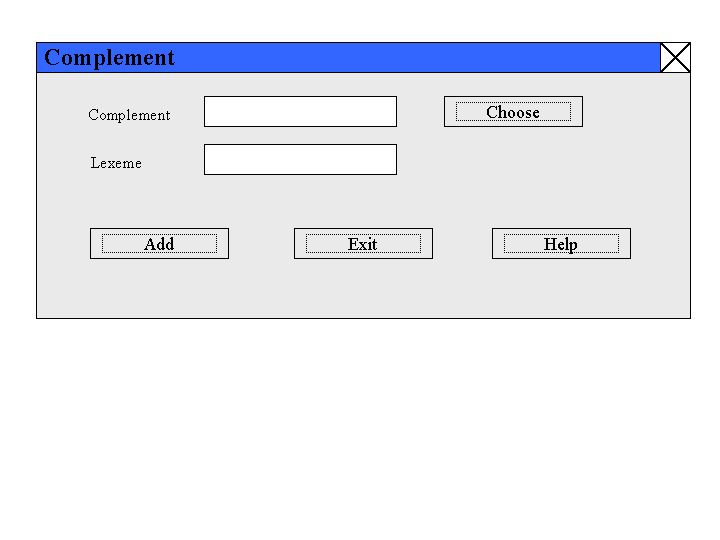
Die erforderlichen Eingaben (Lexeme, Reading, Category, Example) werden in die Maske eingegeben, die dazugehörigen Komplemente und Adjunkte wählt der Benutzer durch Mausklick. Die ausgewählten Komplemente und Adjunkte erscheinen dann unter "Show Selection". Durch rechten Mausklick auf ein markiertes Komplement oder Adjunkt kann noch ein Lexem hinzugefügt werden. "Add New Entry" speichert dann den Eintrag im korrekten Klammerausdruck in der Projektdatei.
Die Projektdatei kann dann auf Doubletten geprüft werden, und es kann automatisch eine Wortliste aller bereits kodierten Lexeme erstellt werden.
Die Projektdatei kann aber auch von Hand im Projektfenster weiter bearbeitet werden.
Ausblick:
Alle in der vorgegebenen Ziele wurden erreicht. Durch mehrere Tests mit und ohne Daten konnte die Eingabemaske optimiert werden, so daß das Kodieren möglichts zeitsparend ist.
Eventuell könnte die Doublettenprüfung optimiert werden, um die Verarbeitungzeit bei großen Datenmengen zu verkürzen. Zur Zeit wird bei der Prüfung die ganze Projektdatei von Anfang bis Ende auf doppelte Einträge hin durchsucht, die doppelten Einträge werden dann gelöscht. Durch optimierte Suchroutine könnte die Prüfung schneller werden.
Das Tool ist noch erweiterbar, z. B. wäre eine Komponente sinnvoll, die aus Texten etc. automatisch Wortlisten für die Kodierung einliest.